
I have recently worked on designing a large scale low latency system that can handle a million & more requests per second with 99 percentile latency below 30 milliseconds and can scale horizontally. It was an ambitious & challenging project because we wanted to scale without much increase in the server cost. We already had an efficient Real-time Bidding platform which was improved a lot in the last 4-5 years in multiple iterations. But since last year, I started to sense that it’s becoming more challenging to optimize it further so we began to look for substitutes.
After a lot of thoughts, POCs, and based on past learning, we decided to redesign and rewrite the complete RTB platform. It was a bold move and there was a lot on stake. But it was essential in making us future-ready. It took nearly six months to complete this project and it turned out to be better than our initial expectations. It got released a few months ago. A moment of relief for me and a proud moment for the whole team 🙂
In this article, I will explain some of the learnings that we had through this journey and the different principles and steps that we followed.
- Application design
- Programming Language choice
- Software development & profiling
- Hardware tuning
- Passion
Application design
I believe that good design is key to efficient software and a large scale system is no exception. I am a great fan of OpenResty (Nginx + Lua) web platform and some of the design in our new platform was inspired by it.
Before designing a large scale system, it’s important to understand the type of workload, nature of business, restrictions & privileges that you get. All these things play a very crucial role and can significantly influence the overall scale. e.g. a Critical system like defense or payment will be different from an e-commerce system design or a database system design will be different from a data analytics platform or a batch processing system will be different from a real-time system. You should follow the restriction but also try to utilize all the privileges that you have.
Our RTB platform receives continuous bid requests from many fleets of large servers (Google, Twitter, etc) that expect a response in real-time (usually in a few milliseconds). We need to process everything and make bidding decisions within the given timeline otherwise that bid response will be rejected.
The most important aspects of our design are:
- Task-based thread pool: We have divided complete workflow into a few individual types of tasks and each type of task is executed by a dedicated thread pool e.g. message decoding, network IO, file IO, business logic, etc. Each thread of a pool processes a specific type of task and then passes it on to the next thread pool for further processing and then that thread picks the next task of the same type. We have divided the tasks very carefully. More types of tasks will require a more dedicated thread pool which means more context switch which will increase CPU load so we tried to keep it minimal.
- Non-blocking: We have adopted non-blocking application design so that the task threads of the different pools are never (or minimal) in the wait state which makes application latency low & predictable. We have used non-blocking or asynchronous APIs wherever possible and added strict timeouts when using synchronous APIs. We avoided the synchronized data structure as much as possible and preferred push-based approach over pull which gives threads more time for actual work rather than being idle and waiting for the response.
- Data structure: For a large scale system, the correct choice of the data structure for a task is very important. We have experimented with few open-source high-performance data structures to replace the traditional ones. All these steps helped us to keep application latency in check. We usually don’t bother much about the time and space complexity of an operation on a data structure but here it can be really costly to overlook even a small part. For example, the contains() method on List runs in O(n) not O(1). We can use Set instead of List where contains() runs in O(1). You can run benchmarks to see the huge performance difference on a large scale. Now you know why time complexity analysis is important 🙂
Benchmark Mode Cnt Score Error Units CollectionsBenchmark.testArrayList avgt 20 57499.620 ± 11388.645 ns/op CollectionsBenchmark.testHashSet avgt 20 11.802 ± 1.164 ns/op
Reference: https://www.baeldung.com/java-hashset-arraylist-contains-performance
- Reuse & memoization: We have focused a lot on reusing objects to avoid unnecessary object creation. We cached a lot of values to avoid repetitive expensive computations or calls. It helped us to reduce the overall memory footprint & CPU utilization of the application.
- Be a pessimist: If something can break then it will. If not today then tomorrow. You should consider all the adverse situations and add precautionary measures accordingly. It will help to avoid unexpected application behaviors. e.g. how will your application behave when there is a problem in the downstream pipeline or what if a database query is stuck for a long time or what if there is a network or power outage in your data center or what if disk IO is suddenly very slow. These things are very crucial for an application that is deemed to be live 24*7.
Programming Language choice
In the last 10 years, I got the opportunity to work with a lot of programming languages. From famous languages like C/C++, C#, Java, Golang, Scala, Python, JS, PHP to odd ones like Lua, *Tcl, *Assembly, *Pascal, etc. Each one of them has its own benefits and constraints. The existing platform was written in Lua with some C wrappers. It had worked really well until now. The main problem we faced with Lua was that there is no (or relatively low) support from library developers like new DB connectors or some new language support that can utilize recent advancement in OS or hardware. I had to write some of the libraries that I couldn’t find or was of low quality to use in our application e.g. Json parser. So I decided to try a new language which meets these criteria:
- High performance
- Mature & large community support
- Language under active development
- Familiar to team
- Smaller development cycle
My final list based on these conditions was – C++, Golang & Java. I always prefer C/C++ when performance is paramount criteria but it has a large learning curve and things can go haywire quickly if you don’t have a very experienced team so I moved to the next option. We already have a few services which are using Golang for a few years. I like it. It’s really easy & quick to write a high-performance application using Golang. It has exciting features that helped it to grow it’s community fast. But I personally feel that it’s not as seasoned as C/C++ or Java and it requires more support from the community to grow its ecosystem of high-performance libraries and tools. We had quickly scaled our services using Golang but struggled to scale it further. Our next nominee was Java. Well, I personally would not have favored any VM based language for our application but I had recently studied some high-performance low latency applications developed in Java in the High-Frequency trading & Finance domain. They had displayed exciting results and it was satisfying all our criteria so we decided to try it for another project as POC before the main project. We experimented with a lot of things like different JVMs, GC policies & parameters, high-performance data structures, different application designs, etc, and then we finally settled for Java. All of it was possible because of the large and mature community of Java. There is a lot going on in the Java world. I am really impressed by the two new garbage collectors – Shenandoah & ZGC (experimental). * = Minor experience
Software development & profiling
We have used Performance-driven development (PDD) with Iterative and incremental development.  We had divided the complete code into smaller units and started development from the most basic part. We developed a small unit and then we started the performance test. Once it satisfied the criteria, it was merged to the main code and we repeated the test on the entire code developed so far and then we moved to the next unit. In this way, in every iteration, we knew the bottlenecks and removed them right away. It helped us to identify problems and limitations in very early stages and we had taken the necessary steps at the same time otherwise changing the code in a much later stage would have been very difficult and could have required a complete redesign. We have used Linux perf and Flamegraph extensively along with standard Java tools like jmap and jprofiler for application profiling. These tools are very helpful to identify different problems in code that are difficult to detect in static code analysis. Sometimes it’s not our code but the third-party library that we are using is the real culprit. You can find which part of code is more CPU intensive or which thread is stuck or which object is occupying more memory. Most of the time, you can fix them easily by simple code modification or design change. If you don’t find anything useful or suspicious in the User space flame graph, oftentimes the Kernel space flame graph can be the savior. This is the sample of the kernel space flame graph that I generated a few years ago.
We had divided the complete code into smaller units and started development from the most basic part. We developed a small unit and then we started the performance test. Once it satisfied the criteria, it was merged to the main code and we repeated the test on the entire code developed so far and then we moved to the next unit. In this way, in every iteration, we knew the bottlenecks and removed them right away. It helped us to identify problems and limitations in very early stages and we had taken the necessary steps at the same time otherwise changing the code in a much later stage would have been very difficult and could have required a complete redesign. We have used Linux perf and Flamegraph extensively along with standard Java tools like jmap and jprofiler for application profiling. These tools are very helpful to identify different problems in code that are difficult to detect in static code analysis. Sometimes it’s not our code but the third-party library that we are using is the real culprit. You can find which part of code is more CPU intensive or which thread is stuck or which object is occupying more memory. Most of the time, you can fix them easily by simple code modification or design change. If you don’t find anything useful or suspicious in the User space flame graph, oftentimes the Kernel space flame graph can be the savior. This is the sample of the kernel space flame graph that I generated a few years ago. 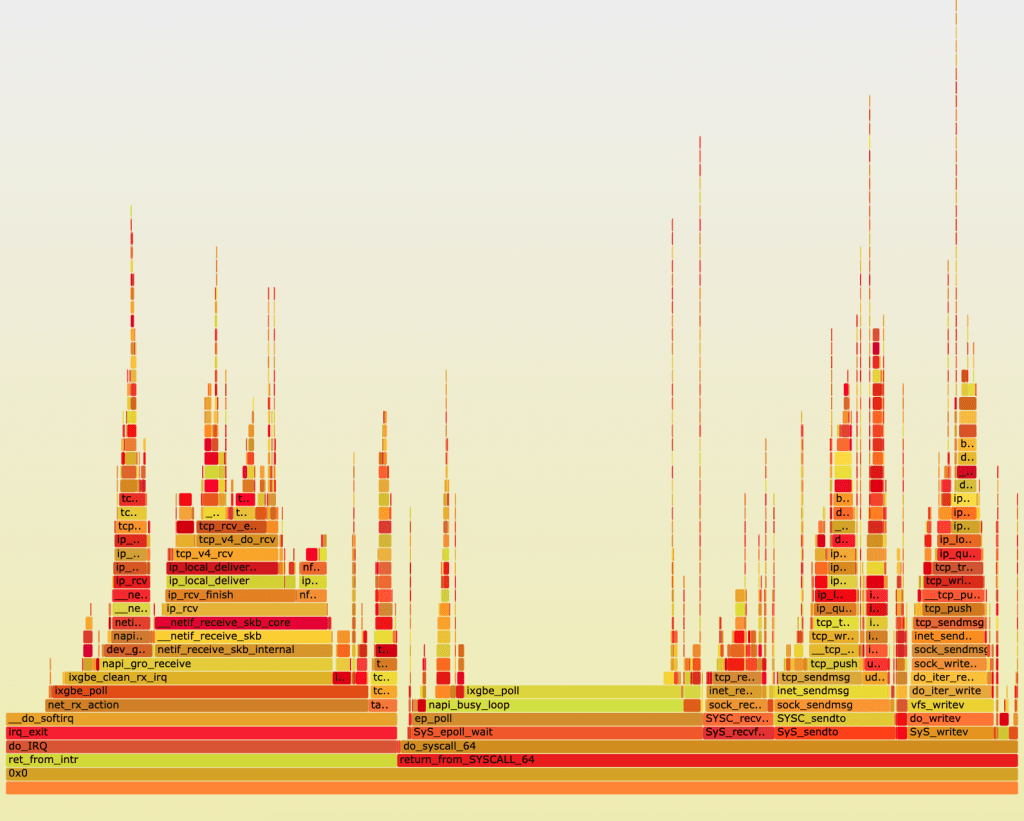
Hardware tuning
A software executes on hardware. RAM, CPU, Storage unit, network, etc all of them directly impact application performance. Based on the nature of the application it may differ but one way or another your application performance is bound by quality, quantity & performance of respective hardware. Let’s take the example of a database system. You can introduce a lot of improvement in your software/application like caching, sharding, efficient data format, etc but eventually, data should be written to a persistent storage system like a storage device and if it’s not on par with the application TPS, you can’t do much. You may use a better HDD or try an SSD which can improve performance without any code changes. Likewise, if your application is CPU or Memory bound, you can add more CPU or RAM to your system and it will perform better. But obviously you can’t keep adding hardware resources. In my experience sometimes, contrary to general belief, upgrading hardware turns out to be more economical than adding more commodity servers. e.g. upgrading a 24 core server to 48 core can give you twice the performance gain at a much cheaper price than adding a new server. But it highly depends on your application. So, you should experiment with these things. Apart from adding extra hardware, most of the Linux OS distros provide customization or configurable options to the user which can be used to tweak the system performance. Some distros have bundled some common tuning parameters in a specific profile which can be accessed and applied using tuned-adm utility.
# list all available profile $ tuned-adm list # To switch to a different profile $ tuned-adm profile <profile-name>
There are a lot of good articles on the internet about Linux OS & hardware tuning. Please read it. It will definitely help you. Some examples are: https://access.redhat.com/sites/default/files/attachments/20150325_network_performance_tuning.pdf https://www.kernel.org/doc/Documentation/cpu-freq/governors.txt
Passion
Although it’s a behavioral trait I strongly believe that it has a huge impact on the quality of work. It motivates you when you feel there is no way around.
“Study the past if you would define the future ― Confucius”
We read a lot of articles, documentation and the source code of good software projects and we experiment with them to prove our understanding. It’s very important to keep us updated with the fast-changing technologies. Every day there is something new or useful out there which can help us today or tomorrow. We had some good learning from others and from our past experience that helped us to make good decisions. We are handling more than a million QPS smoothly with P99 latency below 5ms (ignoring occasional GC spikes that are within the limit) across multiple data centers. I feel that there is still a lot of scope of improvement. We will work on it.


