Apache-Airflow is an open-source software created by Airbnb and has been developed for building, monitoring, and managing workflows. Airflow is also being widely adopted by many companies including Slack and Google (Google Cloud Composer has chosen Airflow as its default workflow management system).
Why Kayzen adapted Airflow?
“After adapting to Airflow, one of our many achievements at Kayzen has been scheduling a large number of parallel jobs without the need to tackle deadlocks or complicated code blocks. We have been able to’ increase the efficiency of some of our ETLs by more than 50 percent with ease.” – Servesh Jain, Co-Founder & CTO @Kayzen
ETL pipelines are one of the most commonly used day-to-day process workflows in a majority of IT companies today. ETL refers to the group of processes that includes data extraction, transformation, and loading from one place to another which is often necessary to enable deeper analytics and business intelligence.
Kayzen’s state of the art prediction models are trained on real time data, which also creates a need to reprocess delayed data, an example of delayed data would be billing of impressions, which can take place up to 48 hours after bidding. This creates a necessity to reprocess the previous 2 days of data every hour so that we have updated data. Since we deal with Big Data, faster and easily manageable workflow management systems are needed to efficiently deal with all our scheduled ETL.
Adapting to Airflow, has helped us in efficiently building, scaling, and maintaining our ETL pipelines with reduced efforts in infrastructure deployments and maintenance. Airflow gives us the ability to manage all our jobs from one place, review the execution status of each job, and make better use of our resources through Airflow’s inbuilt parallel processing capabilities.
Earlier we were using Jenkins to build our ETL pipelines. Jenkins is an automation server used for continuous-integration and continuous-deployment (CI/CD). By default, Jenkins does not provide any workflow management capabilities, and so we had to add plugins on top of it to manage our workflows. But this was just making things harder to manage.
To clarify my point I will describe certain scenarios we encountered during our work, which made us rethink our work methods.
Scenario one: To create upstream & downstream jobs i.e triggering a job after a particular job finishes, we need a dependency plugin.
Scenario two: A certain job X that runs every hour, calculates some parameters and produces some results, or collects some data; How do we pass those parameters or results to the next job?
Scenario three: Reprocessing the data for the last Y days and parallel processing Z tasks.
Scenario four: Due to some issues in network connection, a job fails. How do we retry the job without manually running it each time something fails?
Scenario five: Easily accessing all the task-related logs from one place.
For every additional feature we wanted, an additional plugin is needed to keep things moving smoothly – at some point, additional scripting was needed to make things workable. Adding more and more plugins just added to the complexity of the system, making it rather difficult to manage our workflows.
While working on a POC, we found that Apache Airflow came as a really good solution to tackle this problem: based on our use-cases and the management issues we faced with Jenkins just vanished. A decent understanding of python and SQL was more than enough to set up and use for Airflow.
Airflow has a wide community of active developers to provide bug fixes and support, which made debugging issues much easier.
How Airflow Works?
Airflow uses the concept of DAGs (Directed Acyclic Graph) and Operators (constructors for creating nodes in the DAG) to schedule jobs.
Operators are functions that are designed to perform a particular task, to clarify:
- SSHOperator helps, connect to a server over SSH, and executes specified commands
- DockerOperator for executing a command inside the docker container
- HiveOperator for executing HQL code or hive script in a specific Hive DB
Airflow also offers the flexibility to create custom operators based on our requirements.
Let us first understand a basic Airflow workflow through an example:
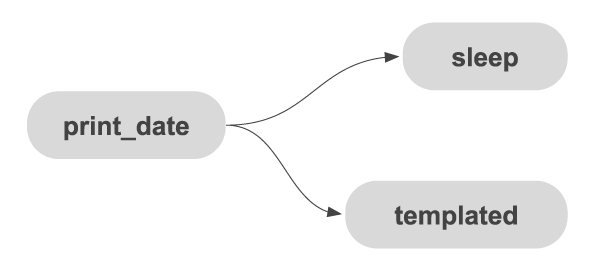 Here, we have code for a DAG with 3 BashOperators (BashOperator executes bash commands), a task print_date being an upstream job would be executed first, followed by sleep and templated. We can also specify conditions in downstream jobs for each task, for example, we can set a condition that sleep executes only if print_date is successful.
Here, we have code for a DAG with 3 BashOperators (BashOperator executes bash commands), a task print_date being an upstream job would be executed first, followed by sleep and templated. We can also specify conditions in downstream jobs for each task, for example, we can set a condition that sleep executes only if print_date is successful.Few Important Features of Airflow
XCom: (cross-communication mechanism between tasks) – so let’s assume that print_date in the above example is over and we want to send that data to the task template, we can do this through XCom. This makes it perfect for scenarios where the output of an ETL process serves as an input for another. Backfilling: running tasks with a custom time frame specified by users, has never been so easy. We also have the freedom to either backfill the entire DAG or just a particular task in the DAG. We use this property to reprocess historical data after adding a new feature or for coping up with data loss. Concurrency: Airflow also provides the comfort of managing concurrent parallel tasks as part of the DAG definition. Unlike Jenkins, we didn’t need to click n pages to finally reach the output page in Airflow, since all the scheduled runs associated with the DAGs are available inside the tree view which makes it very easy to navigate and access all the logs.
Case Study
Now, consider an ETL job that
- Stacks data from the data warehouse
- Makes some transformations
- Saves it into a database
Let us look at a code snippet for (1 – Stacking data) to get some code visibility:
pullData = """ sh pull_data_from_database.sh {{ ds }} if [[ $? -eq 0 ]]; then echo “pull data executed” else exit 1 fi """ def pull_data(connection_id, **kwargs): return SSHOperator( ssh_conn_id=connection_id, task_id="pull_data_from_db", trigger_rule=TriggerRule.ALL_SUCCESS, command=pullData, dag=dag) pull_data() >> [process_data_1(), process_data_2(), process_data_3()] >> purge_old_data() >> taskFailed
Here, we have a function pull data which returns an SSHOperator, executes the command “pullData” on the connection_id (connection id is used to identify the server) passed to it, and “pullData” is a bash script which calls the script followed by a check to see if the script is executed successfully.
pull_data_from_database.sh
Python’s Jinja template provides the flexibility of parsing the scheduled date, run time, etc. within tasks and templating configurations within shell snippets inside the main code. >> , << operators are used for specifying upstream and downstream between different tasks.
{{ ds }} - is Jinga Templated date argument, in YYYY-MM-DD format by default.
In the example above there‘s as a downstream job which in turn runs purge_old_data as a downstream job.
pull_data runs process_data_1, process_data_2, process_data_3
 Airflow makes it easy to visualize this workflow. The dark green border on pull_data_from_db indicates that the job has run successfully whereas the light green borders indicate that process_data_1, process_data_2, and process_data_3 are running parallelly. Airflow also provides some cool visualization features like Gant Chart and Landing Times to help users understand the time taken by each task in the DAG. So, at any instant, a user can see if the data transformation process has completed at an instant, whereas in Jenkins we had to add an explicit plugin just for the pipeline view.
Airflow makes it easy to visualize this workflow. The dark green border on pull_data_from_db indicates that the job has run successfully whereas the light green borders indicate that process_data_1, process_data_2, and process_data_3 are running parallelly. Airflow also provides some cool visualization features like Gant Chart and Landing Times to help users understand the time taken by each task in the DAG. So, at any instant, a user can see if the data transformation process has completed at an instant, whereas in Jenkins we had to add an explicit plugin just for the pipeline view. 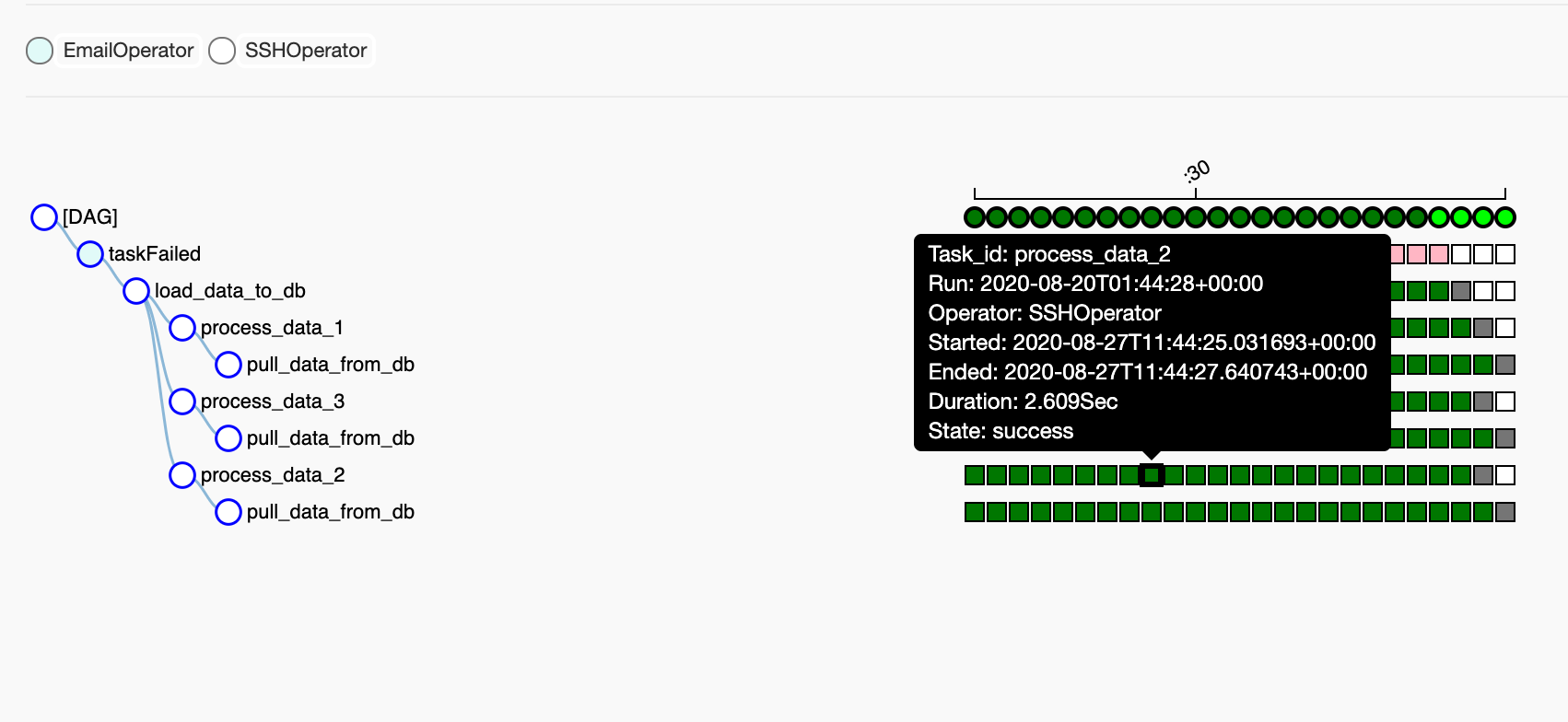
Conclusions
We have been able to increase code performance by improving our resource utilization the easy way through airflow’s concurrency management. Using this to our advantage, we have been scheduling many ETL jobs on airflow and are continuously improving it. For example, one of the use cases we had was a training job that usually takes up to six hours to process one hour of data. With Airflow, we were able to orchestrate easily, and parallel process the same amount of data within twenty minutes through concurrency management. Another feature that made a yet deeper impact was visualization. In this case, we were fetching big chunks of data and applying transformations, in parallel utilizing all the cores of our server; Airflow’s rich UI helps us review what all tasks run at an instant, what all tasks were stuck in retries and the ones that are successfully executed. This helps debug issues faster and improve our design architecture. 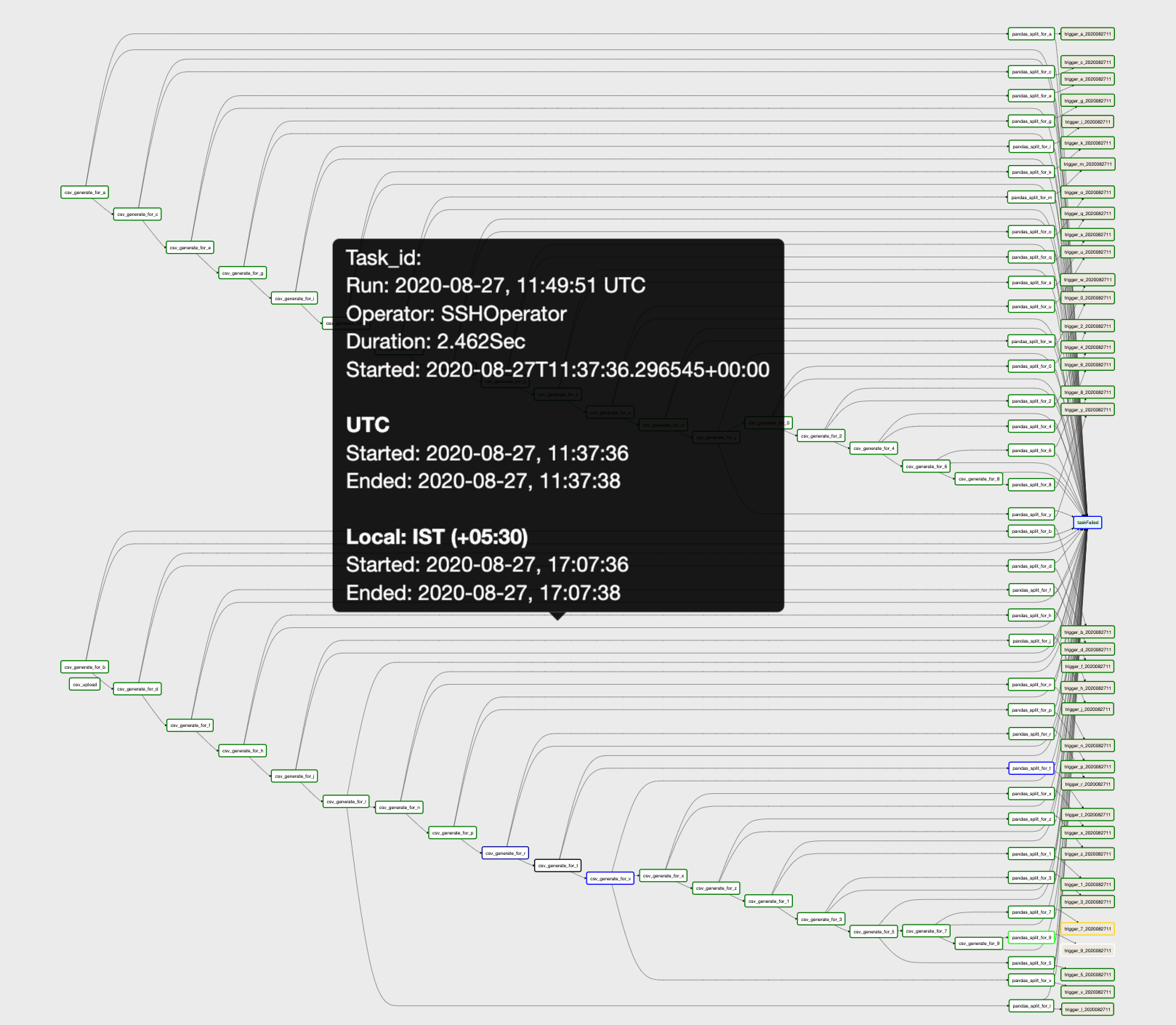 By now, we have deployed many complex workflows on Airflow. There are still many areas for us to explore. And even though there are areas of improvement on the UI, we believe that Apache-Airflow is a powerful tool that makes workflow management comfortable.
By now, we have deployed many complex workflows on Airflow. There are still many areas for us to explore. And even though there are areas of improvement on the UI, we believe that Apache-Airflow is a powerful tool that makes workflow management comfortable.


